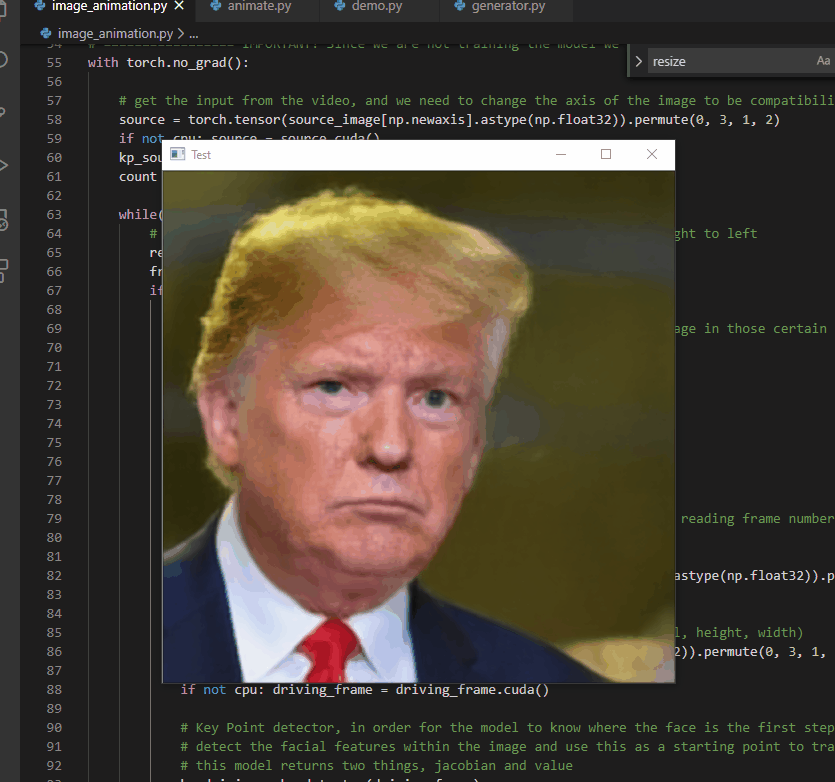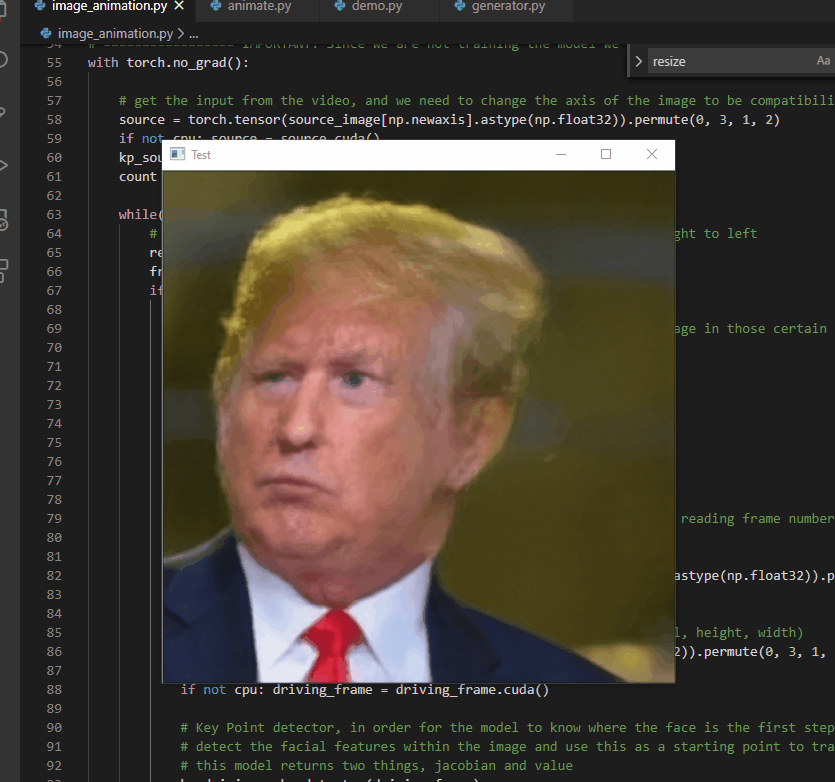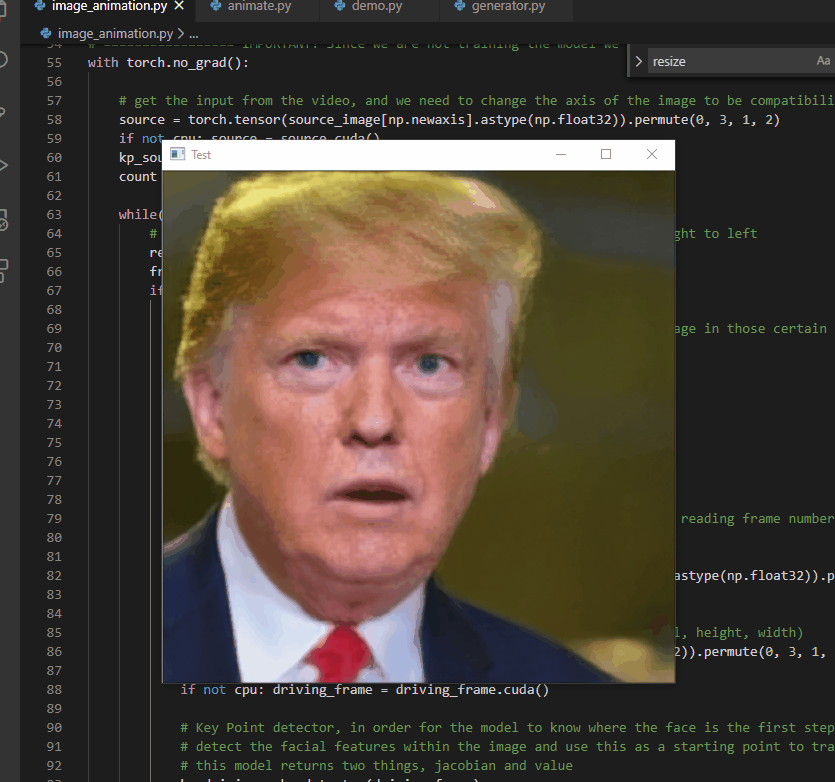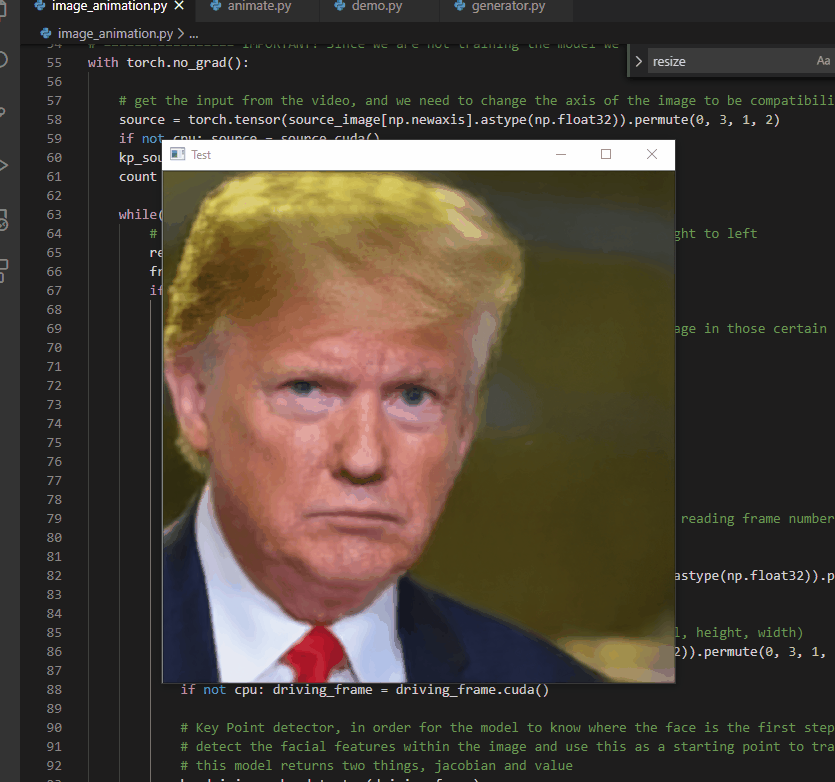
Deepfakes present the opportunity to re-create versions of partially-captured historical events in which only audio of the event exists. With this in mind, Jae Seo and I built a proof-of-concept titled “He Said”. The prototype uses the image of U.S. President Donald Trump in front of St. John’s Church (Washington D.C.) and uses deepfake technology to have him speak the audio of the Access Hollywood Tapes. This example of a deepfake gives a moving image to an otherwise audio-only capturing of the event, placing the words into a bodily context, potentially increasing the verisimilitude of that capturing of the event, and thereby, hopefully, strongly critiquing the misogynistic words of Donald Trump

This deepfake was made by, first, downloading all of Donald Trump’s weekly Presidential addresses from YouTube (https://www.youtube.com/watch?v=0Xoqwsd15BQ&list=PLkwy2e0kOHTwhWwLfuvTgSv29MpXv0dA5) totalling over 5 GB of video data. These videos were chosen largely because of their video and audio quality, but also that Trump’s face is centred in the frame and facing the camera for the majority of the recordings. We then used face swapping technology, based on recommendations from Sergio Canu’s article “Face Swapping (in 8 easy Steps) – Open CV with Python” (https://pysource.com/2019/05/28/face-swapping-explained-in-8-steps-opencv-with-python/), based on Thin-Plate-Spline-Motion-Model (https://github.com/yoyo-nb/Thin-Plate-Spline-Motion-Model). We then trained our own model of Trump speaking utilizing the video and audio from Trump’s weekly Presidential addresses so as to produce a reasonable facsimile of how Trump speaks. He then recorded Jae speaking the transcript from the Access Hollywood Tapes then swapped the resulting face onto the image of Donald Trump talking in front of St. John’s Church. We then placed the original audio underneath the video so that the deepfake appeared to speak the audio in Trump’s voice.
To be clear, this is a prototype and a proof of concept. The technology we were using at the time has since improved and our hopes is that other research creation and/or artists take this as a template for a more robust example of this type of deepfake.